- 将Linux中的“工具箱”翻个底朝天 - 操作系统 - Linux
littlebat注:此文以在linux的控制台终端用mp3blaster播放音乐为例说明screen的高级应用,screen的基本用法参见:linux下的多窗口程序sceen的使用简介
(tags: linux screen mp3blaster)
- UbuntuHelp:FirefoxPlugins/zh - Ubuntu中文
本页的内容是基于Mozilla Firefox浏览器支持Ubuntu并提供技术支持的版本,例如从Ubuntu知识库(repositories)中的Firefox安装包(package)。本文假设用户使用 包管理工具来安装或升级插件。如果您使用其它
- 安装MPlayer - Ubuntu中文
littlebat注:在ubuntu下安装mplayer
分类:开源
在linux下使用mplayer播放影音(links for 2007-09-22)
- MPlayer compiling error [Archive] - Ubuntu ForumsError: X11 support required for GUI compilationI managed to fix it by installing the following packages
xorg-dev (x windows devel kit)
libgtk2.0-dev (gtk devel kit) - Centos 5下的mplayer的安装(RHEL同样合适),中文支持.. - linux和类Unix系统配置优化 - 扶凯linux下的是影音风景就是mplayer,没有不对播放的
...
New_Face failed.Maybe the font path is wrong.
Please supply the text font file(~/.mplayer/subfont.ttf).
解决方法是
cd /usr/share/fonts/chinese/TrueType/
cp ukai.ttf ~/.mplayer/subfo - 中国Linux公社 - 自由软件2.下载:MPlayer-1.0pre7
http://www4.mplayerhq.hu/MPlayer/releases/MPlayer-1.0pre7.tar.bz2
官方CODES-all
all-20050412.tar.bz2
官方win32_CODES-all
windows-all-20050412.zip
字体
gb2312-ming.tar.bz2
皮肤
Blue-1.4.tar.bz2 - Linux操作系统环境下看流媒体的方法介绍 方法 介绍 流媒体 环境 操作系统 Firefox 可以 播放 地址 | Linux中国比如: mplayer和Xine.
1.安装 mplayerplug-in for mozilla
...
2.安装 Firefox 扩展mediawrap
...
3. 为Firefox添加rtsp和mms协议
试试安全、开放的firefox浏览器吧!
Firefox浏览器,也就是“火狐浏览器”。我用了有几年了,有一些心得和感想,概而言之就是:安全、开放、自由。详情如下:
一、相对比较安全。
1、很多针对IE的病毒在firefox身上不起作用,主要是firefox不运行极不安全的ActiveX插件,免疫网页病毒、木马。
而有些网页病毒、木马就是您打开防病毒软件也不起作用,像有一次我用IE打开一封邮件,结果中了“番茄花园”病毒,弄得我重装系统 ;还有一次用IE浏览一个网站的后台帐号管理页面时,杀毒软件连报两个病毒!
所以,现在有些网站挂了木马什么的(有被动和主动两种),您用IE浏览的话,保不准哪天就中了招。像在现在的谷歌搜索结果中,对一些可能有危害的网站标上“该网站可能含有恶意软件,有可能会危害您的电脑。”,打开链接像下面这样的,如果必须查看的话,这样的网站用firefox去“深入虎穴”可能要保险一点。
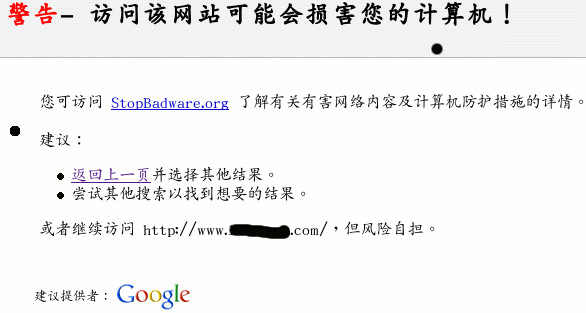
所以,如果常在网上冲浪,搜索资料,最好是用firefox浏览器增强安全性。
二、firefox是开放源代码项目,它是一个开放的平台,全世界任何一个人都可以在上面增加您的扩展(extensions)、插件(plugins)、定制您的主题(themes),几乎可以说,“只有您想不到的,没有firefox做不到的“,来享受一下DIY的快乐吧 🙂 相关的知识您可以看看 这里:firefox附加软件,还有月光博客的这篇提高浏览体验的五十个最佳FireFox扩展插件也值得一读。
所以,如果您是一个程序员,您喜欢hacking,那么,挑战一下开放的firefox浏览器吧。
三、使用firefox,尝试一下不同于windows世界的另一种风格。
四、firefox的问题。
由于IE已经造成的垄断局面,一些不符合W3C标准的极少数网站可能只能用IE浏览,用firefox可能会出问题。如:点不到链接、表格变形等等。但是仅是极少数,用firefox来上网查资料、冲浪应该是不会受到明显影响的。
五、下载。
点击这里下载共41种语言3种操作系统(windows, Mac Os X, Linux)下的firefox。
下载带有google工具栏的firefox。Google工具栏是google公司在firefox上集成的一系列有用的工具,如:搜索,即时翻译,书签,显示当前浏览页的pagerank值等等。点击这里下载。
ps: 这篇百度的贴吧文章在激烈的讨论浏览器,有兴趣去看看:挑战IE的声音:Firefox到底好在哪里?
如果您对浏览器有什么不同的见解,欢迎留言交流。Good luck!
wordpress+盘古,不错的blog系统
使用wordpress+盘古的blog系统可能有半月了吧。总的来说,感觉二者的组合是好用的blog系统,不错的blog系统。
wordpress的blog程序的强大我最有感触的几点是:
1)、模板、插件应有尽有;
2)、功能完善,定制容易,如果自己不满意某个地方,您尽可以在它的代码随意修改;
3)、权限设置、私人日记、受密码保护日记的功能很贴合我的需要;
盘古的虚拟空间我最有感触的几点是:
1)、功能完备,使用方便,所有的网站管理功能(域名绑定、数据库建立和管理、文件管理、备份、访问统计等等)基本上都可以在他们的cPanel控制面板动动鼠标就搞定;
2)、售后服务比较迅速,我提在他们的在线问答上的问题能及时响应;
3)、提供的.htaccess支持使我的新老URL都能顺利访问,并且有利于搜索引擎优化;
我还感到比较满意的一点是:二者在我的linux控制台下基本上都能方便的使用,我原来还想,wordpress的功能这么完备,在文字模式的linux控制台下不知能不能写日记啊?可现在,我目前发现除了文件的上传功能我在linux控制台下的w3m浏览器不支持IFRAME而不能使用外,其它所有功能都工作得很棒。呵呵,这篇日记就是我在linux控制台下写的。而盘古的cPanel本来就是工作在他们的linux下的,在我的linux控制台下使用起来当然是流畅极了:)。一句广告语:wordpress + 盘古,powered by linux,it's OK!
当然,世间之事怎么能完美?!在半月内,我也碰到过两三次网站短时间不能访问的情况,但这是正常之极,我也不以为怪。况且,盘古的系统也很便宜,100块一年的,像我这样的博客足足有余了。当然,如果您的博客红得像“老徐”的博客,那就另当别论了:)
一句话:wordpress+盘古,不错的blog系统!
感觉学习日记的设计形式有点笨重了
学习日记软件的帖子组织形式有点笨重,很多时候,日记就那么一两句话,而如果作为一篇日记放在一页的话,觉得有点太浪费空间了。一个页面的大部分内容是导航,实际的内容很少。像http://www.43things.com等网站一个目标就是一句话,而下面的每日的记录都在同一页的这个目标下面。
这两天,有个很明显的感觉就是:难以动手记点东西。不是不想记,而是由于上面的原因,觉得一两句话就记一篇日记不好。
不过,学习日记已经设计成这个样子,除非以后重写程序,这样的形式还是要继续的。
这里采取一个变通的方式:
在大目标下,征对自己当前正在着手解决的问题写成一篇日记,后续的思考记成日记的评论,这样,一篇日记在一个页面就不过分了。
另外,在目标下,开一个帖子,名为:JAVA小技巧汇总,育儿每日一句,英语每日一句,eclipse使用小技巧,等等。
这样,我就不会有下手为难的感觉了。
毕竟,我不是在写教学文章,我在记日记,记自己的点滴心得和一步一步的足迹。
以后,学习日记重新设计的时候,要考虑把帖子的组织形式做成大众化,轻量级的,使所有的朋友乐于留言和互相鼓励。只有这样,才能实现我们提倡的学习方式:分享目标,分享快乐。
静态页面嵌入jsp动态页面的一些总结和疑问
用在一个实现将JSP动态页面转为静态的方案(转帖)中后面的那种方法基本上完成了本站的动态页面静态化工作,下面是一些总结和疑问。希望能给碰到类似情况的朋友一点启发。也希望有朋友能够启发一下我在文中提到的疑问。谢谢。
1、页面菜单上部的用户信息是用iframe嵌入的,像下面:
|
/common/userState.jsp是从当前session中取出用户的相关信息显示出来。
不过,我发现: 在firefox中位置不动的信息条在IE中却可以用鼠标上下移动,而且,始终位置在底部,还把字脚给挡住了,搞不懂怎么做了?(注:这个问题已经解决,见:怎样控制iframe内嵌网页的位置
,2006年12月29日10:30分, littlebat)
2、显示日记或目标的帖子下面的游客回复框也是用iframe嵌入的,像下面:
|
这个有几点自己的总结:
1)、url中文参数的传递要编码:如:
|
使用时再解码,如:
|
2),当前页面处理的信息可以放入pageContext中(如:pageContext.setAttribute("defaultTitle", defaultTitle);),它的作用域应该是当前页面,可以用 <c:out value=""/> 之类的技术取出来,jsp的方法不知道。
3),为了使嵌入的jsp页面中的form提交后能够返回它的被嵌入的_parent页面,可以在form提交时加 target="_parent"解决,如下:
|
3、页面计数:
用script做的,如下:
|
疑问:
1)、怎样在script中调用程序,得到当前页面的实时点击数并写入页面的合适位置?上面的功能只能计数,然后统一生成页面更新计数;
2)、本来上面的count.do可以用count.jsp来做的,也许这样还要好点,但是我不知道怎样在jsp中调用struts中的数据源?用jdbc连接常常形成连接数超出空间允许的最大值而不能正确计数;
在struts的action中这样调用数据源:javax.sql.DataSource ds = getDataSource(request, "myDataSourceName");
4)、当用*.jsp后缀名作为静态文件时,提交新日记或目标后,第一次查看会有编译等待jsp的时间,但是写日记和目标毕竟是很少时候,99.99%的时候还是在看的。选用*.jsp是我动过脑子的,最终要是证明错了我也不后悔。因为,我曾经努力过。
4、因为,听说搜索引擎会跟进frame中的框架页面,也不知道会不会跟进iframe的页面,把那两个动态的jsp页面的url写进了robots.txt中禁止搜索引擎抓取这些没有实际意义的东西。像下面:
|
本站完整的robots.txt见:http://java.learndiary.com/robots.txt。
里面主要禁止搜索引擎访问一些个人才会用的功能,我是第一次写robots.txt,哪位朋友看了发现有问题请一定给我提示一下,谢谢。
页面静态化和网站地图生成,下一步做什么。。。
完成页面静态化和网站地图生成模块的主体部分,思维有点乱,理一下下一步应该做什么。
1、页面静态化:
1)、把登录信息和游客留言的表单、页面计数各写进一个单独的jsp文件,然后用javascript或jframe调用;
2)、为了统一,菜单栏的登录用户能够看见的项目使游客也可看见,减少静态化后页面处理的复杂度;
3)、在目标页面的订阅邮件和退订邮件的提示信息有问题,要修正;
4)、当更新一篇帖子后(修改或发评论后),当前帖子的原来的上一条和下一条帖子、原来的首条帖子都需要重新生成静态文件,不然这几条帖子的上一条、下一条导航要出现问题;考虑生成的时机;
5)、上一条、下一条导航是按默认的最近更新排列的,为了与原来的动态选择排列顺序,考虑是否这种上一条、下一条的导航也用一个单独的jsp文件执行,然后用javascript或iframe调用;
6)、帖子列表是否也静态化,静态化了排序功能就没有了;
7)、删除一篇帖子的评论后不能在当时按设想更新静态文件,所以采取了重新显示帖子的过程中重新生成静态文件,需要找出原因;
2、网站地图生成:
1)、继续完成在提交帖子或更新时的网站地图更新,现在是手动全部一次更新;
3、这两天做静态化都是在网上调试的,还是应该在本地调试好后才传上去为好,免得让来访的朋友看见莫名其妙的东西:)
JAVA学习日记网站地图生成模块方案
JAVA学习日记网站地图生成模块设计
想法太多,想法太成熟,只会使事情停滞不前。不管怎样,先把网站地图生成模块做一个出来再说。
为了使导航更加方便用户和使搜索引擎更好的遍历,设计网站地图模块。
为了灵活性起见,网站地图同样采用前面的静态页面生成方法,生成的静态文件采用jsp文件,再在生成的文件前面加上通过控制语句(比如301转向,使本站的网址统一在域名:http://java.learndiary.com/下)。
一)、需求:
需要生成的网站地图采用树型结构。
一个所有目标地图goals-1.jsp(http://java.learndiary.com/sitemaps/goals-1.jsp),包括全部公共目标的链接(标题含链接)、创建者,创建日期,日记数目,查看次数;或者就是链接:“目标:学习Jsp的所有日记”,这个页面的标题就叫<a href="http://java.learndiary.com/" title="分享目标,分享分享快乐。">JAVA学习日记</a>所有目标列表
这个网页的title就写作:JAVA学习日记所有目标列表(一) - JAVA学习日记网站地图
每100个目标一页,然后第二个一百页就是goals-2.jsp,以此类推。
然后就是各个目标的日记列表地图:如goal1-1.jsp(http://java.learndiary.com/sitemaps/goal1-1.jsp,为goal加上目标的ID加上页码,每100篇日记1页,以此类推)。
每个目标标题的链接到这个目标的所有日记列表。
这个页面的标题就叫:目标:<a href="" title="">学习Jsp</a>的所有日记列表(一)
这个网页的title就写作:目标:学习Jsp的所有日记列表(一) - JAVA学习日记网站地图
二)、实现:
网站地图生成与维护由MapGenerator.java负责。
它的功能有:
public static void doPostArt(ArticleInfo postedArt, TransContext trans)
throws Exception {}
public static void doEditArt(
ArticleInfo oldArt,
ArticleInfo newArt,
TransContext trans,
HttpServletRequest request)
throws Exception {}
public static void doDelArt(
ArticleInfo delArt,
TransContext trans,
HttpServletRequest request)
throws Exception {}
public static void updateAll(TransContext trans) throws Exception {}
public static boolean isExist(
String fileVirtualName,
HttpServletRequest request) {}
public static void delete(
String fileVirtualName,
HttpServletRequest request) {}
MapGenerator.java将调用一次或多次CallHtml.java中的 public static void callOnePage(String fileName, int artID, int pageNum)方法,来产生相应的一页或多页jsp静态页面(当条目数超过100条时(SITEMAP_ENTRIES_NUM=100))。
而CallHtml.java将调用MapGenerateAction.java来生成相应的动态页面,以此来生成静态的页面。在其中应该注意私有的日记和目标不能生成网站地图。
MapGenerateActon的调用形式可以是: mapGenerateAction.do?artID=1&pageNum=1
整体思路与前两天的JAVA学习日记页面静态化方案类似,生成的时机也类似,不过有不同的地方就是一个目标可能要生成不止一篇列表。
mapGenerateAction需要产生一些数据供实际显示内容的动态jsp文件(这里命名为:siteMap.jsp)
根据前面的需求,产生siteMap.jsp需要的数据包括:
1)、地图的类型:是目标列表还是日记列表,这由artID来定,artID=0表示显示目标列表;artID!=0表示显示所代表的目标的日记列表;
2)、页码:因为一个目标的日记数可能超过100,所以需要根据页码产生当前页。
3)、为了显示页的标题,需要把当前目标传入,类型是ArticleInfo,至于显示所有目标的列表的地图的标题可以造一个ArticleInfo。其中要包括含有的条目数;条目数大于100就要在标题中显示下一页的链接;
4)、目标下面包含的条目信息,是一个以ArticleInfo为子元素的List。
上面1)和2)可以从参数parameter中取得,3)和4)则必须从request.getAttribute()中取得;
CallHtml.java中的 public static void callOnePage(String fileName, int artID, int pageNum){}
fileName可以是siteMap,artID和pageNum的含义同上面的mapGenerateAction.do?artID=1&pageNum=1一样。
而CallHtml的callOnePage方法调用的实际生成jsp静态页面的程序是:
public class ToHtml extends HttpServlet{}
原来的这个类只生成帖子内容的html文件,现在的区别是在生成的静态文件头部额外加上一段jsp公共处理程序,然后把文件扩展名改为:jsp。
在MapGenerator.java中针对每种情况的处理都要考虑有时一个目标的页面生成过程要调用不止一次。这就需要在方法中判断列表的帖子数是否大于SITEMAP_ENTRIES_NUM=100,然后根据列表的帖子数决定调用几次CallHtml中的callOnePage()方法。
下面就开始动手编码吧。
An error happend in setEntries() of RSSGenerator.java
|
RSS订阅在thunderbird中有时会出现丢失条目的情况,但是在新浪点点通和其它RSS阅读器中又没有发现问题。
而且,我时不时在网站日志中发现上面的错误信息“An error happend in setEntries() of RSSGenerator.java”。
现在把它记在这里,好好查一查,说不定能找出在thunderbird中RSS订阅有问题的情况。
也许,我中了seo的毒了?
从理论上讲,www.javaeye.com的静态文件列表对搜索引擎来说有内容复制之嫌疑。
如:这篇帖子:confluence不支持群集,是因为hibernate吗?
在静态文件列表中是:http://www.javaeye.com/t/20169.html
而在动态文件列表中是:http://www.javaeye.com/topic/20169
也就是说,相同的内容在他们页面有两个版本,一个动态的,一个静态的。
我不知道这对它们在搜索引擎中的收录有什么影响?
也许,我现在考虑搜索引擎考虑得太多了。
像这两天又想在虚拟主机提供商端实现彻底的301重定向,但是到现在为止也还没有成功。
做网站,或者更坦白的说,学习知识的我不应该在为迁就搜索引擎而折磨自己了。
还有,我发现一个著名的linux个人站linux.vbird.org,他有两个域名:http://linux.vbird.org和http://www.vbird.org,进入都是同样的返回200 ok状态码;还有他的文章如: DNS 伺服器設定 两个域名都返回的是200码
http://www.vbird.org/linux_server/0350dns.php
http://linux.vbird.org/linux_server/0350dns.php
也就是说,也有内容复制之嫌。
但是以“DNS 伺服器設定”为关键字检索site:linux.vbird.org有结果,而site:www.vbird.org却没有这篇文章的影子,只有这篇文章的老版本:http://www.vbird.org/linux_server/0350dns/0350dns.php存在,而且,这篇老文章被标记成了补充材料。
另外,另一篇文章(Enterprise Linux 实战讲座前言DNS 反解( Reverse Lookup )原理)的pdf文件:
http://linux.vbird.org/somepaper/20050630-dns-1.pdf分在了linux.vbird.org,
而同样文章的第二部分却分在了:www.vbird.org/somepaper/20050630-dns-2.pdf
但是他还不是照样很红火?
我想,是google根据判断把本来是一个站的内容分在了两个域名下。
说明这还是有问题的,我上vbird.org问一下站长vbird的想法如何?
也许,正如:SEO每日一帖的zac说的那样,我中了SEO的毒了?