Two years past, I suddenly found may be the key of LearnDiary's lacking hot.
The key is no a specialized location for website, so no the specialized friends participate this website.
So, I am doing some changes these days, I think the work I have finished the most part.
Another found for learning english, I found a method of learning english at website: http://seawan.nyist.net/kle/index.php, it is saying, he, you can learning english well by see film. I will try it, is it a real way for me to learn english? Only the time can answer.
Happy these days!
完成分组后台管理及目标修改代码
进行了征对 issue 21 的第二次大的cvs提交。
下面需要完成首页的目标分组及其下的目标的显示代码,只涉及到一个类文件和一个页面文件;
把孩子送到外婆乡下去玩了
昨天,她和她外婆、表姐一起到大孃家过国庆节去了。乡下清山绿水,孩子肯定喜欢,而且这个季节又没有什么蚊子了。
倒转接硬盘数据线导致ATA66变成ATA33
80线的IDE硬盘连接线,因为我怀疑那段长的那边可能接触不良,于是我把原来接第二块硬盘那端的接头接到主板的IDE接口上。结果发现硬盘的ATA66变成了ATA33,按原来的接法接就又成了ATA66。可能是倒过来接就成40线的数据线吧。不懂还是别乱试的好,免得到时后悔。
mysql中的max_connections和max_user_connections
max_connections是指整个mysql服务器的最大连接数;
max_user_connections是指每个数据库用户的最大连接数,比如:虚拟主机可以用这个参数控制每个虚拟主机用户的数据库最大连接数;
****************************************************************************
设置最大连接数的方法:
转自:fanqiang.chinaunix.net/a2/b1/20010705/140800801.html
加大mysql的最大连接数
本文出自: 作者: (2001-07-05 14:08:00)
mysql的最大连接数默认是100, 这个数值对于并发连接很多的数据库应用是远远不够
的,可以把它适当调大,
whereis safe_mysqld
找到safe_mysqld的位置,然后编辑它,找到mysqld启动的那两行,在后面加上参数
-O max_connections=1000
例如
--- safe_mysqld.orig Mon Sep 25 09:34:01 2000
+++ safe_mysqld Sun Sep 24 16:56:46 2000
@@ -109,10 +109,10 @@
if test "$#" -eq 0
then
nohup $ledir/mysqld --basedir=$MY_BASEDIR_VERSION --datadir=$DATADIR \
- --skip-locking >> $err_log 2>&1
+ --skip-locking -O max_connections=1000 >> $err_log 2>&1
else
nohup $ledir/mysqld --basedir=$MY_BASEDIR_VERSION --datadir=$DATADIR \
- --skip-locking "$@" >> $err_log 2>&1
+ --skip-locking "$@" -O max_connections=1000 >> $err_log 2>&1
fi
if test ! -f $pid_file # This is removed if normal shutdown
then
然后关闭mysql重启它,用
/mysqladmin所在路径/mysqladmin -uroot -p variables
输入root数据库账号的密码后可看到
| max_connections | 1000 |
即新改动已经生效。
*************************************************************************
另,从网上查到一篇介绍mysql参数说明的帖子很好,转帖在此:
转自:http://kb.discuz.net/index.php?title=MySQL%E5%8F%82%E6%95%B0%E8%AF%B4%E6%98%8E
MySQL参数说明
Wikipedia,自由的百科全书
原文地址:http://sunsite.mff.cuni.cz/MIRRORS/ftp.mysql.com/doc/en/SHOW_VARIABLES.html
1. back_log
指定MySQL可能的连接数量。当MySQL主线程在很短的时间内得到非常多的连接请求,该参数就起作用,之后主线程花些时间(尽管很短)检查连接并且启动一个新线程。
back_log参数的值指出在MySQL暂时停止响应新请求之前的短时间内多少个请求可以被存在堆栈中。如果系统在一个短时间内有很多连接,则需要增大该参数的值,该参数值指定到来的TCP/IP连接的侦听队列的大小。不同的操作系统在这个队列大小上有它自己的限制。试图设定back_log高于你的操作系统的限制将是无效的。
当观察MySQL进程列表,发现大量 264084 | unauthenticated user | xxx.xxx.xxx.xxx | NULL | Connect | NULL | login | NULL 的待连接进程时,就要加大 back_log 的值。back_log默认值为50。
2. basedir
MySQL主程序所在路径,即:--basedir参数的值。
3. bdb_cache_size
分配给BDB类型数据表的缓存索引和行排列的缓冲区大小,如果不使用DBD类型数据表,则应该在启动MySQL时加载 --skip-bdb 参数以避免内存浪费。
4.bdb_log_buffer_size
分配给BDB类型数据表的缓存索引和行排列的缓冲区大小,如果不使用DBD类型数据表,则应该将该参数值设置为0,或者在启动MySQL时加载 --skip-bdb 参数以避免内存浪费。
5.bdb_home
参见 --bdb-home 选项。
6. bdb_max_lock
指定最大的锁表进程数量(默认为10000),如果使用BDB类型数据表,则可以使用该参数。如果在执行大型事物处理或者查询时发现 bdb: Lock table is out of available locks or Got error 12 from ... 错误,则应该加大该参数值。
7. bdb_logdir
指定使用BDB类型数据表提供服务时的日志存放位置。即为 --bdb-logdir 的值。
8. bdb_shared_data
如果使用 --bdb-shared-data 选项则该参数值为On。
9. bdb_tmpdir
BDB类型数据表的临时文件目录。即为 --bdb-tmpdir 的值。
10. binlog_cache_size
为binary log指定在查询请求处理过程中SQL 查询语句使用的缓存大小。如果频繁应用于大量、复杂的SQL表达式处理,则应该加大该参数值以获得性能提升。
11. bulk_insert_buffer_size
指定 MyISAM 类型数据表表使用特殊的树形结构的缓存。使用整块方式(bulk)能够加快插入操作( INSERT ... SELECT, INSERT ... VALUES (...), (...), ..., 和 LOAD DATA INFILE) 的速度和效率。该参数限制每个线程使用的树形结构缓存大小,如果设置为0则禁用该加速缓存功能。注意:该参数对应的缓存操作只能用户向非空数据表中执行插入操作!默认值为 8MB。
12. character_set
MySQL的默认字符集。
13. character_sets
MySQL所能提供支持的字符集。
14. concurrent_inserts
如果开启该参数,MySQL则允许在执行 SELECT 操作的同时进行 INSERT 操作。如果要关闭该参数,可以在启动 mysqld 时加载 --safe 选项,或者使用 --skip-new 选项。默认为On。
15. connect_timeout
指定MySQL服务等待应答一个连接报文的最大秒数,超出该时间,MySQL向客户端返回 bad handshake。
16. datadir
指定数据库路径。即为 --datadir 选项的值。
17. delay_key_write
该参数只对 MyISAM 类型数据表有效。有如下的取值种类:
off: 如果在建表语句中使用 CREATE TABLE ... DELAYED_KEY_WRITES,则全部忽略
DELAYED_KEY_WRITES;
on: 如果在建表语句中使用 CREATE TABLE ... DELAYED_KEY_WRITES,则使用该选项(默认);
all: 所有打开的数据表都将按照 DELAYED_KEY_WRITES 处理。
如果 DELAYED_KEY_WRITES 开启,对于已经打开的数据表而言,在每次索引更新时都不刷新带有
DELAYED_KEY_WRITES 选项的数据表的key buffer,除非该数据表关闭。该参数会大幅提升写入键值的速
度。如果使用该参数,则应该检查所有数据表:myisamchk --fast --force。
18.delayed_insert_limit
在插入delayed_insert_limit行后,INSERT DELAYED处理模块将检查是否有未执行的SELECT语句。如果有,在继续处理前执行允许这些语句。
19. delayed_insert_timeout
一个INSERT DELAYED线程应该在终止之前等待INSERT语句的时间。
20. delayed_queue_size
为处理INSERT DELAYED分配的队列大小(以行为单位)。如果排队满了,任何进行INSERT DELAYED的客户必须等待队列空间释放后才能继续。
21. flush
在启动MySQL时加载 --flush 参数打开该功能。
22. flush_time
如果该设置为非0值,那么每flush_time秒,所有打开的表将被关,以释放资源和sync到磁盘。注意:只建议在使用 Windows9x/Me 或者当前操作系统资源严重不足时才使用该参数!
23. ft_boolean_syntax
搜索引擎维护员希望更改允许用于逻辑全文搜索的操作符。这些则由变量 ft_boolean_syntax 控制。
24. ft_min_word_len
指定被索引的关键词的最小长度。注意:在更改该参数值后,索引必须重建!
25. ft_max_word_len
指定被索引的关键词的最大长度。注意:在更改该参数值后,索引必须重建!
26. ft_max_word_len_for_sort
指定在使用REPAIR, CREATE INDEX, or ALTER TABLE等方法进行快速全文索引重建过程中所能使用的关键词的最大长度。超出该长度限制的关键词将使用低速方式进行插入。加大该参数的值,MySQL将会建立更大的临时文件(这会减轻CPU负载,但效率将取决于磁盘I/O效率),并且在一个排序取内存放更少的键值。
27. ft_stopword_file
从 ft_stopword_file 变量指定的文件中读取列表。在修改了 stopword 列表后,必须重建 FULLTEXT 索引。
28. have_innodb
YES: MySQL支持InnoDB类型数据表; DISABLE: 使用 --skip-innodb 关闭对InnoDB类型数据表的支持。
29. have_bdb
YES: MySQL支持伯克利类型数据表; DISABLE: 使用 --skip-bdb 关闭对伯克利类型数据表的支持。
30. have_raid
YES: 使MySQL支持RAID功能。
31. have_openssl
YES: 使MySQL支持SSL加密协议。
32. init_file
指定一个包含SQL查询语句的文件,该文件在MySQL启动时将被加载,文件中的SQL语句也会被执行。
33. interactive_timeout
服务器在关上它前在一个交互连接上等待行动的秒数。一个交互的客户被定义为对mysql_real_connect()使用CLIENT_INTERACTIVE选项的客户。也可见wait_timeout。
34. join_buffer_size
用于全部联合(join)的缓冲区大小(不是用索引的联结)。缓冲区对2个表间的每个全部联结分配一次缓冲区,当增加索引不可能时,增加该值可得到一个更快的全部联结。(通常得到快速联结的最佳方法是增加索引。)
35. key_buffer_size
用于索引块的缓冲区大小,增加它可得到更好处理的索引(对所有读和多重写),到你能负担得起那样多。如果你使它太大,系统将开始变慢慢。必须为OS文件系统缓存留下一些空间。为了在写入多个行时得到更多的速度。
36. language
用户输出报错信息的语言。
37. large_file_support
开启大文件支持。
38. locked_in_memory
使用 --memlock 将mysqld锁定在内存中。
39. log
记录所有查询操作。
40. log_update
开启update log。
41. log_bin
开启 binary log。
42. log_slave_updates
如果使用链状同步或者多台Slave之间进行同步则需要开启此参数。
43. long_query_time
如果一个查询所用时间超过该参数值,则该查询操作将被记录在Slow_queries中。
44. lower_case_table_names
1: MySQL总使用小写字母进行SQL操作;
0: 关闭该功能。
注意:如果使用该参数,则应该在启用前将所有数据表转换为小写字母。
45. max_allowed_packet
一个查询语句包的最大尺寸。消息缓冲区被初始化为net_buffer_length字节,但是可在需要时增加到max_allowed_packet个字节。该值太小则会在处理大包时产生错误。如果使用大的BLOB列,必须增加该值。
46. net_buffer_length
通信缓冲区在查询期间被重置到该大小。通常不要改变该参数值,但是如果内存不足,可以将它设置为查询期望的大小。(即,客户发出的SQL语句期望的长度。如果语句超过这个长度,缓冲区自动地被扩大,直到max_allowed_packet个字节。)
47. max_binlog_cache_size
指定binary log缓存的最大容量,如果设置的过小,则在执行复杂查询语句时MySQL会出错。
48. max_binlog_size
指定binary log文件的最大容量,默认为1GB。
49. max_connections
允许同时连接MySQL服务器的客户数量。如果超出该值,MySQL会返回Too many connections错误,但通常情况下,MySQL能够自行解决。
50. max_connect_errors
对于同一主机,如果有超出该参数值个数的中断错误连接,则该主机将被禁止连接。如需对该主机进行解禁,执行:FLUSH HOST;。
51. max_delayed_threads
不要启动多于的这个数字的线程来处理INSERT DELAYED语句。如果你试图在所有INSERT DELAYED线程在用后向一张新表插入数据,行将被插入,就像DELAYED属性没被指定那样。
52. max_heap_table_size
内存表所能使用的最大容量。
53. max_join_size
如果要查询多于max_join_size个记录的联合将返回一个错误。如果要执行没有一个WHERE的语句并且耗费大量时间,且返回上百万行的联结,则需要加大该参数值。
54. max_sort_length
在排序BLOB或TEXT值时使用的字节数(每个值仅头max_sort_length个字节被使用;其余的被忽略)。
55. max_user_connections
指定来自同一用户的最多连接数。设置为0则代表不限制。
56. max_tmp_tables
(该参数目前还没有作用)。一个客户能同时保持打开的临时表的最大数量。
57. max_write_lock_count
当出现max_write_lock_count个写入锁定数量后,开始允许一些被锁定的读操作开始执行。避免写入锁定过多,读取操作处于长时间等待状态。
58. myisam_recover_options
即为 --myisam-recover 选项的值。
(未完成,不断增加中……)
祝大家国庆节和中秋节双节快乐!祝学习日记上线两周年
国庆加中秋,又是双节七天长假,祝大家节日快乐,天天快乐!
学习日记大概是在2004年中秋节上线的,在网上已经跑了两年整了。
感谢所有支持和帮助过学习日记的朋友们!
新的一周年开始了,我们正在进行网站的改版。希望学习日记能真正成为一个有用的东西。对朋友们有所助益。
值得纪念的下午:2006年9月30日,女儿受表扬
因为我们的女儿比较调皮,在原来的幼儿园里被老师看作“不讲道理”的孩子。所以,上了一年幼儿园,还没有得到什么老师的表扬(除了那种小红花)。
但是,今天下午,据她外婆讲,女儿在新幼儿园时真正得到了老师一次隆重的表扬:老师把她一个人叫上讲台,对全班同学说女儿国庆节在班上的舞蹈和唱歌表演中表现出色,大家鼓掌欢迎。于是,下边的小朋友们全都啪啪的拍起手来了。而女儿则昂首挺胸,很是自豪。
我知道是昨天上午进行的班上集体表演。早上送她去幼儿园时因为她有点生病,状态很不好,我给她带手上的花时还不让带左手。我走时她还在哭鼻子。因为担心是不是生病加重了,还给家里打了电话,让去看看孩子,如果情况不好就把她抱到医院去看看...。结果没有想到,孩子后来上场的表现如此之好。唱歌声音响亮,跳舞也卖力。真是想不到呀。
昨天的表演还有一个小插曲。幼儿园的小朋友,女孩子头上要带花。女儿因为夏天怕热,头发理成了男头,结果就带不上花了,让她跟男孩子一样的把花戴在别的位置,站也跟男孩子站在一列。看来,以后要给她把头发留起了。不然,真成了假小子:)
孩子是需要多赞扬和鼓励的,特别是由衷的赞叹和鼓励,对树立孩子的自信心和健全的人格都有重要作用。在陈建翔主编的《家教新主张》系列丛书“父母是孩子的同龄人”中有相关的说法。
在Struts的html:select标签中显示默认值(转)
转自:http://www.theserverside.com/discussions/thread.tss?thread_id=35726
Render default value for html:select in STRUTS
Posted by: Jiao Yu on ?? 07, 2005 DIGG
Hello,
I am trying to render the default value for html:select with STRUTS, but can't get it work correctly.
----------------------------------------------------------
Here are the component I have:
The JSP page to render the html:select
<%@ taglib prefix="req" uri="/WEB-INF/taglibs-request.tld" %>
<%@ taglib uri="/WEB-INF/c.tld" prefix="c" %>
<%@ taglib prefix="fmt" uri="/WEB-INF/fmt.tld" %>
<%@ taglib uri="/WEB-INF/struts-tiles.tld" prefix="tiles" %>
<%@ taglib uri="/WEB-INF/struts-html.tld" prefix="html" %>
<head><title>eQuation 2.0</title></head>
<body>
<html:form action="/mappingAction" >
<table>
<c:forEach var="line" items="${mappingForm.map.matchColumnList}" >
<TR>
<TD><c:out value="${line.databaseColumnNameLabel}"/></TD>
<TD><c:out value="${line.excelColumnPosition}"/></TD>
<TD>
<html:select name="line" property="excelColumnPosition"
multiple="false" size="5" value="${line.excelColumnPosition}" >
<html:option value="" >No Match</html:option>
<html:optionsCollection name="mappingForm"
property="excelColumnList"
value="index"
label="columnName"/>
</html:select>
</TD>
</TR>
</c:forEach>
</table>
<html:submit value="Process"/>
</html:form>
</body>
----------------------------------------------------------
Here is the form setction for my STRUTS configuration xml:
<form-bean name="mappingForm" type="org.apache.struts.action.DynaActionForm" >
<form-property name="excelColumnList" type="rawdata.model.ExcelColumnNameBean[]"/>
<form-property name="matchColumnList" type="rawdata.model.ColumnMatchBean[]" />
----------------------------------------------------------
Here are the definitions for the two beans used in the mappingForm:
public class ColumnMatchBean {
private String excelColumnName;
private String recommmendedDatabaseColumnName;
private String databaseColumnNameLabel;
private int excelColumnPosition;
...}
public class ExcelColumnNameBean {
private String columnName;
private int index;
...}
----------------------------------------------------------
Here is the action mapping used to populate the mappingForm and render the form in a JSP:
<action
path="/loadMatchingColumn"
type="rawdata.LoadMatchingColumnAction"
name="mappingForm"
attribute="mappingForm"
scope="session"
>
<forward name="success"
path="/../upload/showExcelColumns.jsp"
redirect="false"/>
</action>
----------------------------------------------
In LoadMatchingColumnAction, I populated both properties of the mappingForm,
For excelColumnList ( Array of ExcelColumnNameBean), I populated a couple of ExcelColumnNameBean ( with both columnName and index populated),
For matchColumnList ( Array of ColumnMatchBean, I populated a couple of ColumnMatchBean, ( with only recommmendedDatabaseColumnName and databaseColumnNameLabel populated),
Then I the showExcelColumns.jsp, I am going to render a couple of select lists with corresponding labels, see the details of the JSP at the beginning of this POST.
Here my questions come,
1)I can render the couple of select lists successfully, but for each of them, I would like to set a default value, I can't make this to work, although I set the value attribute in the select tag:
<html:select name="line" property="excelColumnPosition"
multiple="false" size="5" value="${line.excelColumnPosition}" >
I wrap select tag with C:foreach tags to render a group of select lists, and the problem seems to happen in
value="${line.excelColumnPosition}"
the correct predefined value can't be retrieved,
If I change "${line.excelColumnPosition}" to a specific number, let's say "2", then it works fine.
How can I get the correct value from line.excelColumnPosition?
2)My second question is: the select list rendered in the JSP page doesn't render a drop down list, but a select box, how can I make it a select drop down list?
Hope I have provided enough and clear information to explain my puzzles?
Thanks so much and have a good night,
Jiao
Message #180699 Post reply Post reply Post reply Go to top Go to top Go to top
Check html:optionsCollection
Posted by: Cliff Liang on ?? 08, 2005 in response to Message #180569
I think you check the following and its tag doc first.
<html:optionsCollection name="mappingForm"
property="excelColumnList"
value="index"
label="columnName"/>
I guess each item in excelColumnList is the pair of index and value. You set value="index", so when you change "${line.excelColumnPosition}" to "2", it works fine.
Try to change to value="value", which is the value of excelColumnPosition is from.
Of course, html:select can be used for drop down list.
Hope it can help you.
Cliff Liang
Message #180705 Post reply Post reply Post reply Go to top Go to top Go to top
RE:Render default value for html:select in STRUTS
Posted by: Jiao Yu on ?? 09, 2005 in response to Message #180569
Cliff,
Thanks for your reply. But I don't think that's the problem, since I already identified the issue under the help of a teammate.
The major issue here is that STRUTS doesn't work well with EL, so ${line.excelColumnPosition}" doesn't work well.
He suggests following options to fix the problem:
a)You must use runtime expression in the value parameter. I have not tested following code.
<bean:define id="defaultValue" name="line" property="excelColumnPosition"/>
<html:select name="line" property="excelColumnPosition" value='<%= defaultValue %>' >
b) Use Struts-EL library
c) Tomcat bundled with JBoss 4.0.2 is 5.5.x. It is Servlet 2.4 and JSP 2.0 compliant. You could change the web.xml to specify the 2.4 version of the servlet specification. EL expresions would be interpreted by the servlet container - Tomcat. The version 2.2 in web.xml does not interpret EL expressions for compatibility reasons.
Changing follow code:
“<!DOCTYPE web-app
PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.2//EN"
"http://java.sun.com/j2ee/dtds/web-app_2_2.dtd">”
To
<?xml version="1.0" encoding="ISO-8859-1"?>
<web-app xmlns="http://java.sun.com/xml/ns/j2ee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee/web-app_2_4.xsd"
version="2.4">
....
</web-app>
------------------------------------------
To dropdown list issue is also resolved, just omit the multiple attribute for select.
Thanks again and happy programming.
Jiao
Message #180707 Post reply Post reply Post reply Go to top Go to top Go to top
Render default value for html:select in STRUTS
Posted by: Jiao Yu on ?? 09, 2005 in response to Message #180569
Hello,
Another tricky thing is :
The var attribute (mathchColumnList)in C:forEach tag, the property after map. for the items attribute (matchColumnList) in the C:foeEach tag, and the name attribute for the html:select tag should be all the same, otherwise, you can't get the POST data in the following action.
<c:forEach var="matchColumnList" items="${mappingForm.map.matchColumnList}" >
<TR>
<TD><c:out value="${matchColumnList.databaseColumnNameLabel}"/></TD>
<TD><c:out value="${matchColumnList.excelColumnPosition}"/></TD>
<TD>
<html:select name="matchColumnList" property="excelColumnPosition"
multiple="false" size="5" value="${matchColumnList.excelColumnPosition}" >
<html:option value="" >No Match</html:option>
<html:optionsCollection name="mappingForm"
property="excelColumnList"
value="index"
label="columnName"/>
</html:select>
Have a good night,
Jiao
走出自己的思维,多向别人学习
网上成功的网站太多了,充满智慧的人也不少。我要走出自己的思维,多与人交流,多向别人学习。比如:多上论坛、blog关注别人的问题和感受。尽自己的力回答一些入门级问题(因为我就是入门级水平)。我想,智慧与智慧的交流对大家都是一种好的状态。我自己需要践行这种理念和状态。
双击驱动器打不开磁盘,出现打开方式对话框
今天在帮一位朋友看电脑时,出现“双击驱动器打不开磁盘,出现打开方式对话框”的怪事,如下图的E盘。这位朋友的电脑中C、D盘双击能打开,但是E,F,G盘就会出现双击打不开的情况,非要右键单击盘符,选择“打开”才能打开磁盘。
朋友原来装的是windows xp sp2,系统中就有这个毛病。我今天去重装了windows xp sp2系统仍是如此。不知是怎么一回事,在网上搜索了下面的地址有相关内容,试了一些方法,没有成功,不是http://www.xiaojb.com/介绍的“AdobeR.exe病毒”和“rose病毒”,只有放在那里了。
好像重新装过的系统不应该有病毒吧。
下面这个方法还没有试,可以试一下。
|
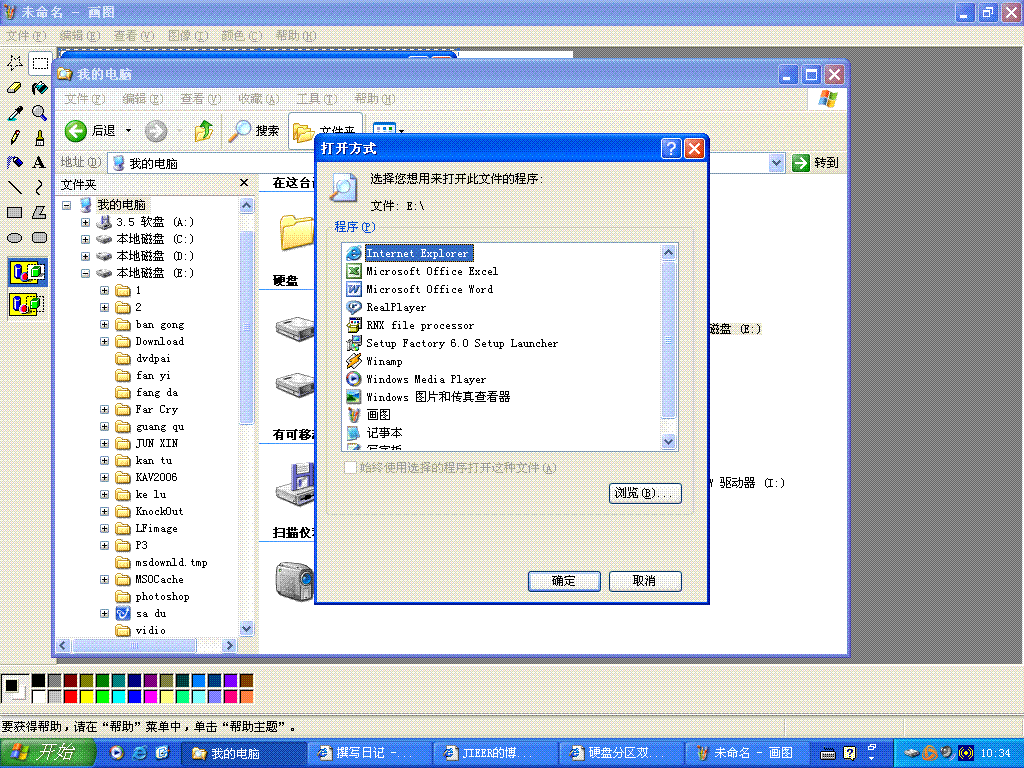
双击驱动器打不开磁盘,出现打开方式对话框图例
一些相关解决方法的网址:
http://www.xiaojb.com/
http://www.7works.com.cn/article.asp?id=223
感叹一下,windows的系统现在用起来真的让人不放心呀,在我接触的好几台windows xp电脑中,安个ewido随便一查,往往就是上百个木马、病毒或是什么有害的玩意儿。另外,其他朋友下的卡巴斯基在系统上查毒往往也有数量巨大的木马、病毒。
现在,搞得要登录一个重要的网页都不敢在windows下面了。我一般都在linux下登录这些网页了。在linux下使用,真的让人觉得比windows踏实多了,杀毒、防木马、防流氓程序,这些在windows下必备的基本功力,在linux下基本上用不着。虽说,linux下现在也不是洁白无暇,但是,我使用linux大概有9个月了吧,还没有碰到上面这些问题。
我还感觉到这些病毒、木马已经不像它们的先辈们,好多是为显示黑客们的威力而生。现在的病毒、木马许多都是窃取密码、锁定网站、强行向用户展示广告。也就是说,他们也走经济利益这条线了。这就是钱啊,谁不想,可就是想得让众人讨厌,成了过街老鼠,人人喊打。他们也许忘了一句古训:君子爱财,取之有道。